
本文摘要:量化大神在萌新期是如何找到众多量化因子的? 〖One〗在寻找因子的过程中,还可以利用各大量化平台,如JoinQuant。这些平台不仅提供基础...
〖One〗在寻找因子的过程中,还可以利用各大量化平台,如JoinQuant。这些平台不仅提供基础因子,还支持API接口,方便获取数据。同时,平台上的“因子看板”功能能够直观展示因子在不同场景下的表现,为策略构建提供宝贵的依据。此外,平台上的因子库,如Barra因子,为构建策略提供了丰富的资源。
〖One〗Stacking集成学习在华泰金融工程研究组研报中的应用学习笔记如下:Stacking集成学习的概念:Stacking是一种机器学习框架,能有效集成多个模型以提升预测准确性和稳定性。它通过在多个基模型的基础上进行二次训练,综合各模型的预测结果,从而得到更优的预测性能。
〖Two〗Bagging:基础:Bagging算法的基础是自助采样法,通过从原始训练集中有放回地抽样,克服样本数量不足的问题。过程:执行自助采样T次,每次使用采样的训练集训练一个分类器。在回归任务中,通过平均多个分类器的预测结果来集成;在分类任务中,采用投票法集成预测。
〖Three〗Stacking:将多个基本学习器的预测结果作为输入,训练一个元学习器进行最终预测。Stacking可以在不同层次上组合多个模型,进一步提高预测性能。它首先将训练数据集分成子集,训练多个基本模型,然后使用这些模型的预测结果作为新特征输入到元模型,得到最终预测结果。
〖Four〗集成学习是一种强大的机器学习方法,主要通过结合多个模型的预测来提高性能和稳定性。我们来看看三种常见的集成学习方法:Bagging、Boosting和Stacking。Bagging,如随机森林,通过构建多个独立且随机的决策树,每个树使用不同的训练数据和特征子集。这种随机性有助于降低过拟合,提高模型的泛化能力。
〖Five〗集成学习通过组合多个模型来提升学习效果。随机森林是一种典型的集成方法,它由多个基础模型如决策树或SVM组成。本文将深入浅出地讲解集成学习的两种主要策略:Bagging和Boosting,以及Stacking。Bagging Bagging主要处理模型复杂度过高导致的方差增大问题。
〖Six〗机器学习中的Ensemble方法主要包括Bagging、AdaBoost、GBDT和Stacking,以下是它们的详细解释:Bagging 核心思想:通过从不同训练集训练多个模型,然后取平均来降低方差,处理模型复杂度过高导致的方差增大问题。 典型应用:随机森林,它通过限制特征选择,生成差异化的决策树,从而降低方差。

咨询记录·解于2021-11-14茅台193...
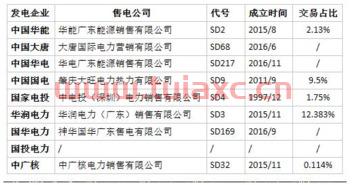
五大四小发电集团名单文章列表:1、2020年五大四小发电集团装机容...
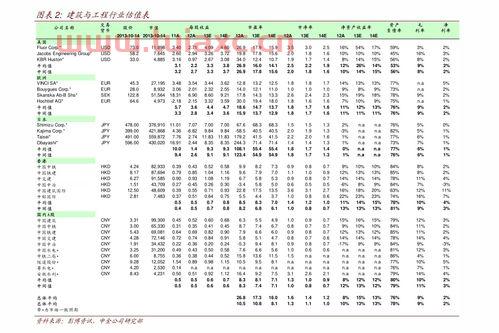
国内油价近二十年历史*价是3.06元一升。*的时候,发生在201...

中信国安(000839)中天科技(600522)新海宜(00...
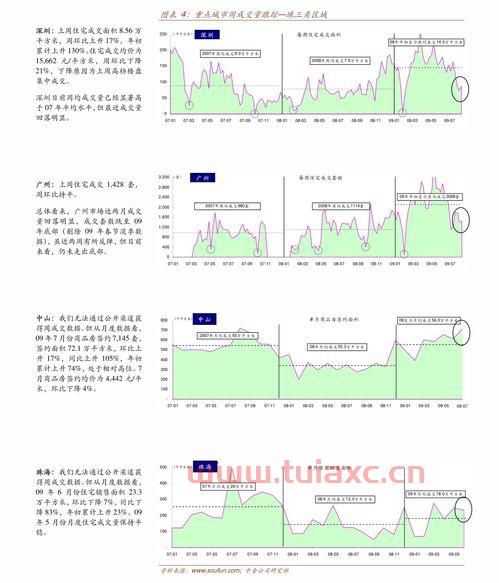
长江铝锭今日价格后面的涨跌是什么意思?是对长江铝锭的一个...
